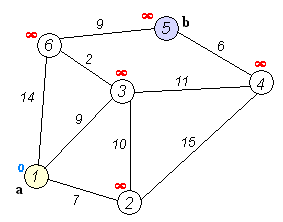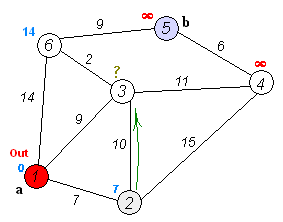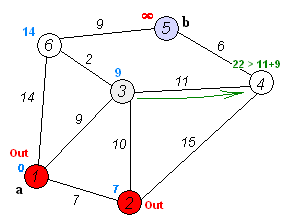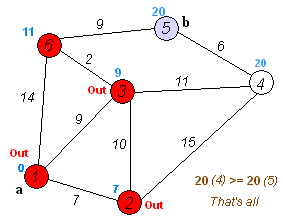
#define INF 1e9
// 거리(가중치) / 노드 번호
vector<vector<pair<int, int>>> graph;
// 최단거리 테이블
vector<int> distances;
void Dijkstra(int start, int numVertices)
{
// 우선순위 큐 (거리 , 노드 인덱스)
priority_queue<pair<int, int>> pq;
// 시작 정점의 거리 0 설정
distances[start] = 0;
pq.push({ 0, start });
while (!pq.empty())
{
// 현재 정점까지의 거리
int currentDistance = pq.top().first;
// 현재 정점
int currentVertex = pq.top().second;
pq.pop();
// 이미 처리된 정점일 경우
if (currentDistance > distances[currentVertex])
continue;
// 현재 정점의 모든 인접 정점 확인
for (pair<int, int>& edge : graph[currentVertex])
{
int weight = edge.first;
int neighbor = edge.second;
// 비용이 더 적은 경로 발견된 경우
if (distances[currentVertex] + weight < distances[neighbor])
{
distances[neighbor] = distances[currentVertex] + weight;
pq.push({ distances[neighbor], neighbor });
}
}
}
}
제자리 정렬 (In-Place Sorting) : 추가적인 메모리 공간을 필요로 하지 않으며, 주어진 배열에서 바로 정렬을 수행한다.
데이터를 비교하며 정렬을 수행한다.
최선,평균,최악의 시간 복잡도는 O(log n)으로 일정한 시간복잡도를 보장한다.
정렬하는 원소가 동일한 값일 경우, 순서를 보장하지 않는다.
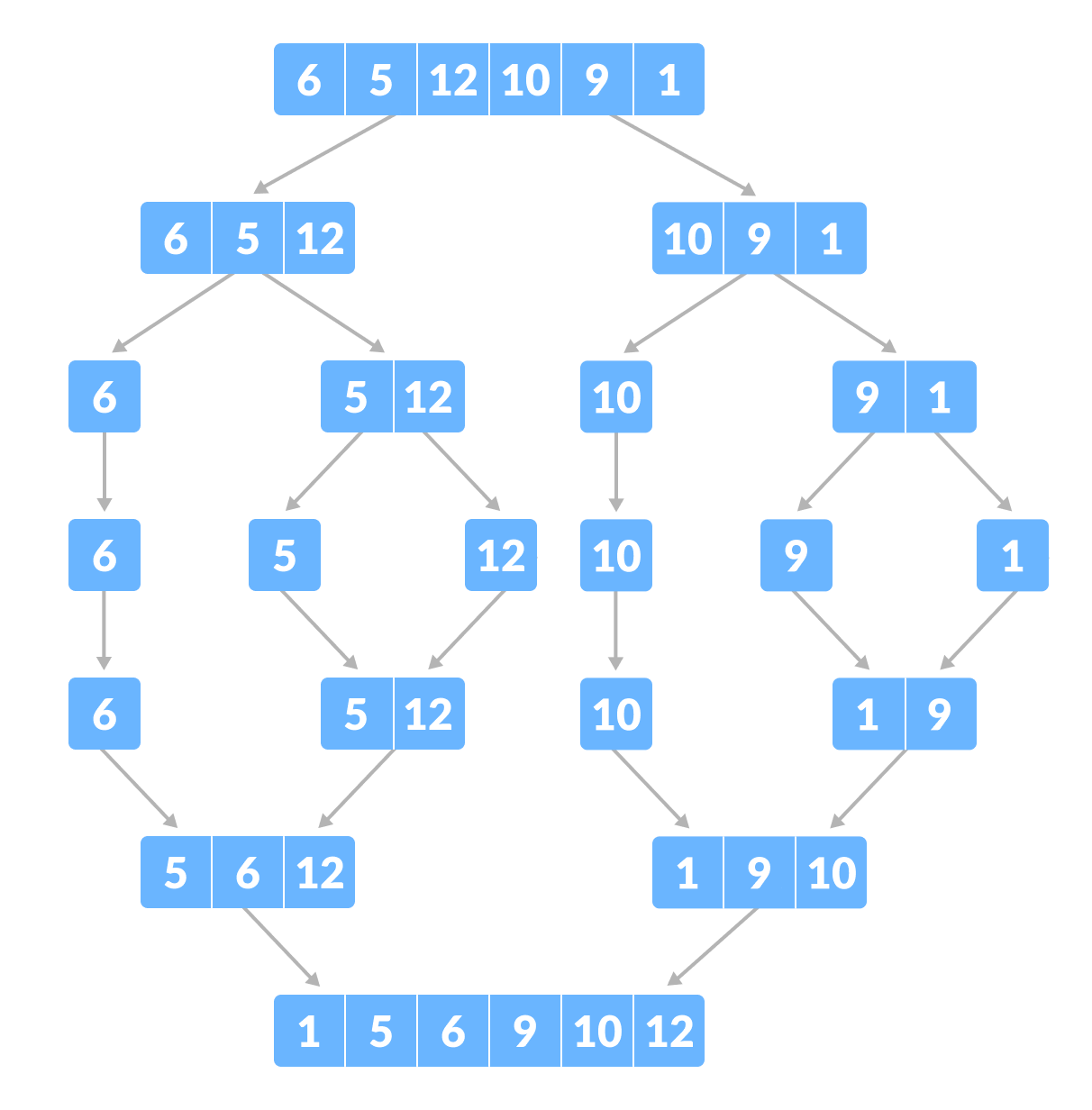
힙정렬 구현
// Heap (완전 이진 트리 형태)
// 정렬할 배열 , 배열의 크기, 루트가 될 원소
void heapify(int arr[], int n, int i)
{
int largest = i;
int left = 2 * i + 1;
int right = 2 * i + 2;
// (right < n && arr[left] < arr[smallest]) -> 최소 힙
if (left < n && arr[left] > arr[largest])
{
largest = left;
}
// (right < n && arr[right] < arr[smallest] -> 최소 힙
if (right < n && arr[right] > arr[largest])
{
largest = right;
}
if (largest != i) {
std::swap(arr[i], arr[largest]);
heapify(arr, n, largest);
}
}
// 힙정렬
void heapSort(int arr[], int n)
{
for (int i = n/2 - 1; i >= 0; i--)
{
heapify(arr, n, i);
}
for (int i = n - 1; i > 0; i--)
{
std::swap(arr[0], arr[i]);
heapify(arr, i, 0);
}
}
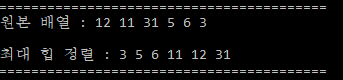
HeapSort - 정렬 결과
병합 정렬 (Merge Sort)
리스트의 원소들을 재귀적으로 반으로 나누고, 각 부분들을 정렬한 후 병합(Merge) 과정을 통해 다시 합치는 방식
분할정복 알고리즘
두 개의 정렬된 리스트를 합쳐서 하나의 정렬된 리스트로 만드는 과정
병합정렬 분할 / 정복 과정- https://anweh.tistory.com/85
특징 및 장단점
분할정복 알고리즘
동일한 값에대한 순서를 보장한다.
리스트를 분할하고 병합하는 단계에서 병렬 처리에 유용하다.
최선,최악,평균 시간복잡도 O(n lon n)을 유지한다.
정렬시 추가적인 메모리 공간이 O(n)만큼 필요하다.
병합정렬 구현
// 병합
void merge(std::vector<int>& arr, int left, int right)
{
if (left >= right) return;
int mid = left + (right - left) / 2;
merge(arr, left, mid);
merge(arr, mid + 1, right);
// 병합 단계
int n1 = mid - left + 1; // 왼쪽 크기
int n2 = right - mid; // 오른쪽 크기
// 임시배열. 공간복잡도 O(n)이 추가적으로 필요한 이유
std::vector<int> leftArr(n1), rightArr(n2);
// 값 복사
for (int i = 0; i < n1; i++)
{
leftArr[i] = arr[left + i];
}
for (int i = 0; i < n2; i++)
{
rightArr[i] = arr[mid + 1 + i];
}
// 두 배열 병합
int i = 0, j = 0, k = left;
while (i < n1 && j < n2)
{
if (leftArr[i] <= rightArr[j])
{
arr[k] = leftArr[i];
i++;
}
else
{
arr[k] = rightArr[j];
j++;
}
k++;
}
// 왼쪽 배열의 나머지 항목 복사
while (i < n1)
{
arr[k] = leftArr[i];
i++;
k++;
}
// 오른쪽 배열의 나머지 항목 복사
while (j < n2)
{
arr[k] = rightArr[j];
j++;
k++;
}
}
// 병합정렬 (분할)
void mergeSort(std::vector<int>& arr, int left, int right) {
if (left < right)
{
int mid = left + (right - left) / 2; // 중간값 계산
mergeSort(arr, left, mid); // 왼쪽 절반
mergeSort(arr, mid + 1, right); // 나머지 오른쪽 절반
merge(arr, left, right); // 마지막 병합
}
}
Stack을 예시로 할 경우 pop함수를 사용하여 저장해둔 값을 꺼내오는데, 이때 pop의 특성은 Stack의 가장 마지막에 들어온 데이터를리턴하며, 삭제하는 구조로 가장 최상위 데이터 하나를 제외한 다른 탐색은 하지않고 즉시 출력값을 얻어낼 수 있습니다.
2. O(log N) - 로그
입력 데이터의 크기가 커질수록 처리 시간이 log만큼 짧아지는 경우에 log 시간을 표현합니다. 대표적인 예시로 BST(Binary Search Tree)가 있으며, 탐색 범위를 절반씩 좁혀가며 데이터를 탐색하기때문에 데이터 개수가 절반씩 줄어든 다는 점, 2배로 늘어나도 나뉘는 수가 1개 더 늘어날 뿐인 점에서 O(log N)이라 표현할 수 있습니다.
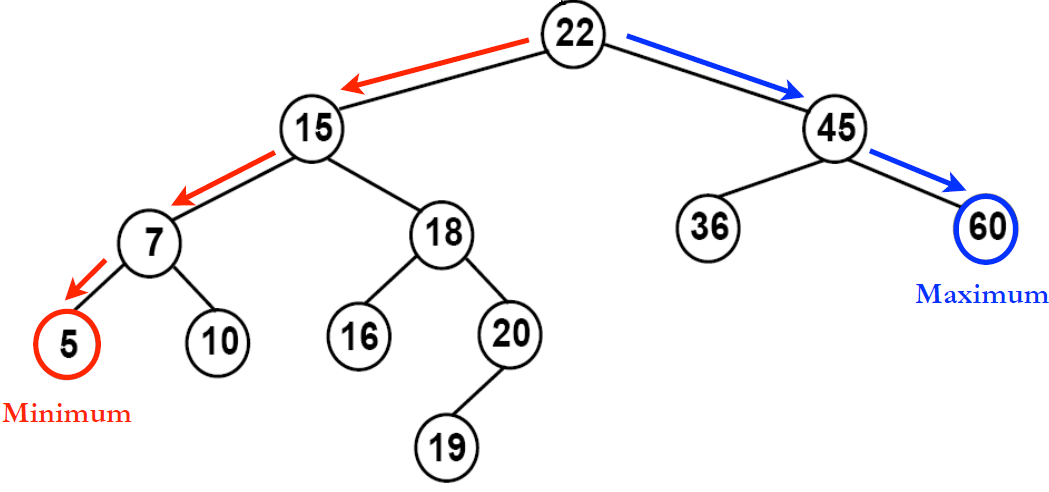
이진탐색트리 (BST)
해당이미지는 이진탐색트리의 예시이며, 탐색하려는 값을 왼쪽에 있는 Branch 부터 비교, 탐색하는 형태로 이루어져 있는 자료구조입니다. BST는 하나의 branch로 치우쳐진 경우 O(n)을 될 수 있지만, 일반적으로는 트리의 높이 h에 따른 최대 노드의 수는 2^h - 1의 개수를 가질 수 있으며, 이로인해 O(log N)이라 표현할 수 있습니다.
3. O(N) - 선형
입력값이 증가함에 따라 시간또한 비례해서 증가합니다.
대표적인 예시로 조건의 값이 참이 될때까지 증감연산을 하는 for문이 있습니다.
4. O(N log N) - 선형 로그
입력 데이터가 많아질수록 처리 시간이 로그 배만큼 늘어납니다.
대표적인 예시로 퀵 정렬(Quick Sort), 병합정렬(Merge Sort), 힙 정렬(Heap Sort)가 있습니다.
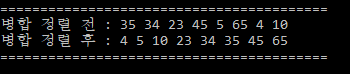
병합정렬의 예시
병합정렬 시간복잡도 예시
병합정렬 (Merge Sort)의 경우 List,Array 등의 저장된 값을 절반씩 나누어 번호순, 사전순과 같이 정해진 순서대로 정렬하는 알고리즘입니다.
정렬된 두 집합을 하나의 정렬된 집합으로 합치는데에 필요한 시간복잡도가 O( 두 집합의 원수의 개수),
그리고 분할 정복을 이용하여 병합정렬을 구현하면 총 시간복잡도가 O(N log N)입니다.
5. O(N²) - 다항
2차 복잡도 라고 부르기도하며, 입력값이 증가함에 따라 시간이 n의 제곱수의 비례하여 증가하는 것을 의미합니다.
대표적인 예시로는 루프 안에서의 루프를 실행하는 이중 for 문이 있습니다.
6. O(2ⁿ) - 지수
기하급수적 복잡도 라고 불리기도하며, Big-O 표기법중 가장 느린 시간 복잡도를 가지고 있습니다.
데이터의 양이 많아질수록 처리시간이 기하급수적으로 증가합니다.
대표적인 예시로는 피보나치 수열이 있습니다.
정리
시간 복잡도는 메모리가 실행되는데 걸리는 시간이 아닌, 메모리의 연산 횟수를 의미한다.
공간 복잡도는 메모리의 사용량을 의미한다.
시간 복잡도와 공간 복잡도는 서로 반비례 형태로 이루어져 있으며,알고리즘의 성능을 최적화 하기위해
두 복잡도를 고려해야한다.
복잡도의 표기법에는 대표적으로 최악의 상황을 고려하는 빅오 (Big-O)표기법이 있으며
사용하는 데이터의 개수와 소모되는 시간에 따라 미분, 적분형식의 그래프 형태를 나타내기도한다.