
프로젝트를 진행하기 전에 내가 어떤 프로젝트를 만들고 어떤 기능을 구현할까.. 라고 생각을 하던 도중
제가 플레이 했던 FPS게임 중 벽이 파괴되어 사실적인 전투를 묘사할 수 있는 게임이 있었습니다.
이러한 기능들을 프로젝트를 진행할 때 구현하고싶어 다양한 방법을 찾아보았습니다.
해당 기법은 Destructible Mesh라고 부르며, 다양한 방법들이 있었습니다.
이번 포스팅에서는 블루프린트를 사용해 구현한 파괴가능한 메시들에 대해 알아보겠습니다.
Destructible Mesh
- 물리적으로 파괴 가능한 3D 모델
- 특정 이벤트에 의해 분해, 재구성되는 특성을 가진다
- 충격, 폭발, 물리적 충돌 등을 통해 모델이 분해되는 방식으로 구현된다
- 파괴된 상태는 메모리에 저장되어 게임 내 파괴된 물체를 다시 불러오는 작업을 할 수 있다.
장점 및 단점
- 플레이어가 물체를 파괴할수있어 게임 내 몰입감을 높이고 물리적 상호작용을 더 다양한 방식으로 표현할 수 있다.
- 런타임 환경에서 파괴하여 플레이 시 생동감있는 표현을 보여줄 수 있다.
- 나무, 금속, 유리 등 각기 다른 재질들의 파괴방식을 다르게 구현하는데 있어 설계의 난이도가 높다.
- 파괴 시 계산하는 작업에 있어 메모리 사용량이 증가하며 성능에 영향을 줄 수 있다.
Dynamic Mesh Component
- 동적 변형이 가능한 메쉬
- 런타임 환경에서 물리적 충격, 폭발 등으로 해당 메쉬를 동적으로 변경할 수 있다 - 1
- 파괴된 조각들이나 물리적 충돌을 처리하는 방식에 있어 성능 최적화가 가능하다.
- 해당 물체의 각 부분을 세밀하게 제어할 수 있기때문에 물리적 처리를 더 디테일하게 조절할 수 있다.
- 런타임 환경에서 실시간 렌더링을 하는 과정 중 성능에 문제가 생길 수 있다 - 2
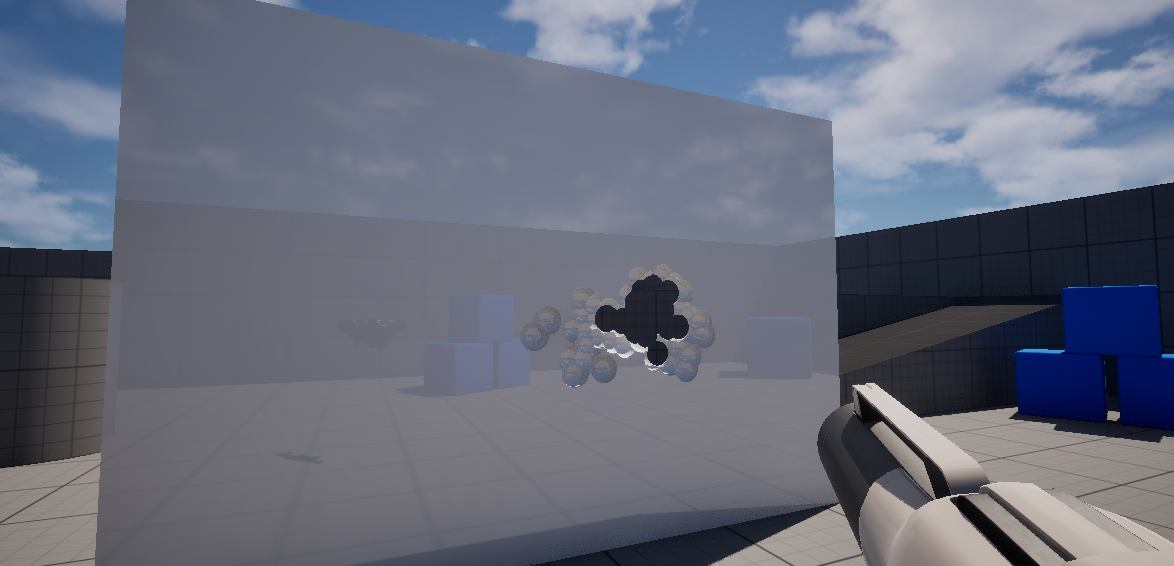
Dynamic Mesh Actor을 사용한 블루프린트 클래스 내 구현
1. BeginPlay
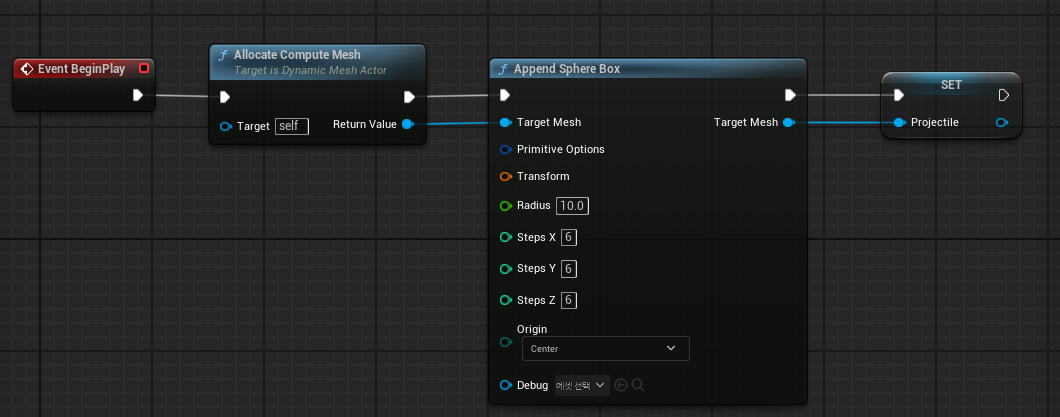
Allocate Compute Mesh : 동적 메쉬의 메모리 할당 및 변형 처리를 담당한다.
Append Sphere Box : Sphere와 Box 두 가지 다른 형태의 충돌 영역을 하나로 결합하며, Sphere와 Box가 충돌될 경우를 처리하기 위해 사용한다.
2.OnRebuildGenerateMesh
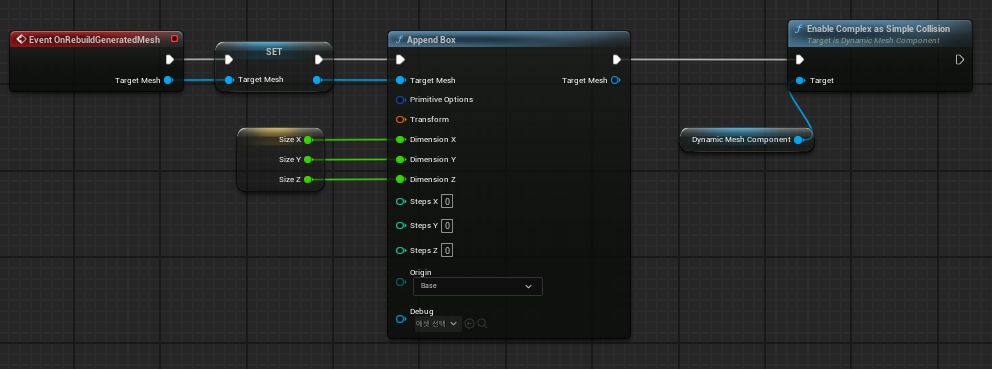
OnRebuildGeneratedMesh : 동적 메쉬가 재구성 시 발생하는 이벤트
Append Box : 여러개의 박스 충돌 영역을 결합하여 충돌범위를 최적화 하는데 사용한다.
Enable Complex as Simple Collision : 복잡한 메쉬 충돌들을 단순한 충돌체로 대체한다. 복잡한 Dynamic Mesh 모델에 대한 물리적 계산을 더 빠르게 처리할 수 있다.
3. Destruction(인터페이스)

Break Hit Result : Collision 발생 시 그것에 대한 정보들을 가지고 있는 구조체
- Location : 충돌이 발생한 위치
- Normal : 충돌 지점에서의 법선 벡터
- Impact Point : 충돌이 발생한 좌표
- Impact Normal : 충돌 지점에서 물체의 표면 법선
- Hit Actor : 충돌한 액터
- Hit Component : 충돌한 컴포넌트
Apply Mesh Boolean : Boolean 연산을 메쉬에 적용하는데 사용되는 함수로 메쉬의 결합, 차집합, 교집합의 작업을 설정할 수 있다.
- Union : 두 메쉬가 겹치는 부분을 포함한 전체 메쉬를 생성한다.
- Subtract : 한 메쉬에서 다른 메쉬의 영역을 빼고 남은 부분을 생성한다.
- Intersection : 두 메쉬가 겹치는 부분만을 포함하는 새로운 메쉬를 생성한다.
https://link.springer.com/article/10.1007/s11042-022-13049-x
'Unreal Engine > Etc' 카테고리의 다른 글
| [UE,게임수학] - 짐벌 락(Gimbal Lock) 오일러 각 (Euler Angles) (0) | 2025.01.23 |
|---|





